Scale an Application with HPA
Implantar um aplicativo de exemplo
Vamos implantar um aplicativo e expor como um serviço na porta TCP 80. O aplicativo é uma imagem customizada baseada na imagem php-apache. A página index.php realiza cálculos para gerar carga da CPU. Mais informações podem ser encontradas Aqui
kubectl run php-apache --image=k8s.gcr.io/hpa-example --requests=cpu=200m --expose --port=80
Crie um recurso HPA
Este HPA aumenta quando a CPU excede 50% do recurso de contêiner alocado.
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
Veja o HPA usando o kubectl. Você provavelmente verá <unknown>/50% por 1-2 minutos e então você deve ser capaz de ver 0%/50%
kubectl get hpa
Gerar carga para acionar o dimensionamento
Abra um novo terminal no Cloud9 Environment e execute o seguinte comando para colocar em um shell em um novo contêiner
kubectl run -i --tty load-generator --image=busybox /bin/sh
Execute um loop while para continuar recebendo http:///php-apache
while true; do wget -q -O - http://php-apache; done
Na guia anterior, observe o HPA com o seguinte comando
kubectl get hpa -w
Você verá a HPA dimensionar os pods de 1 até o máximo configurado (10) até que a média da CPU esteja abaixo do nosso objetivo (50%)
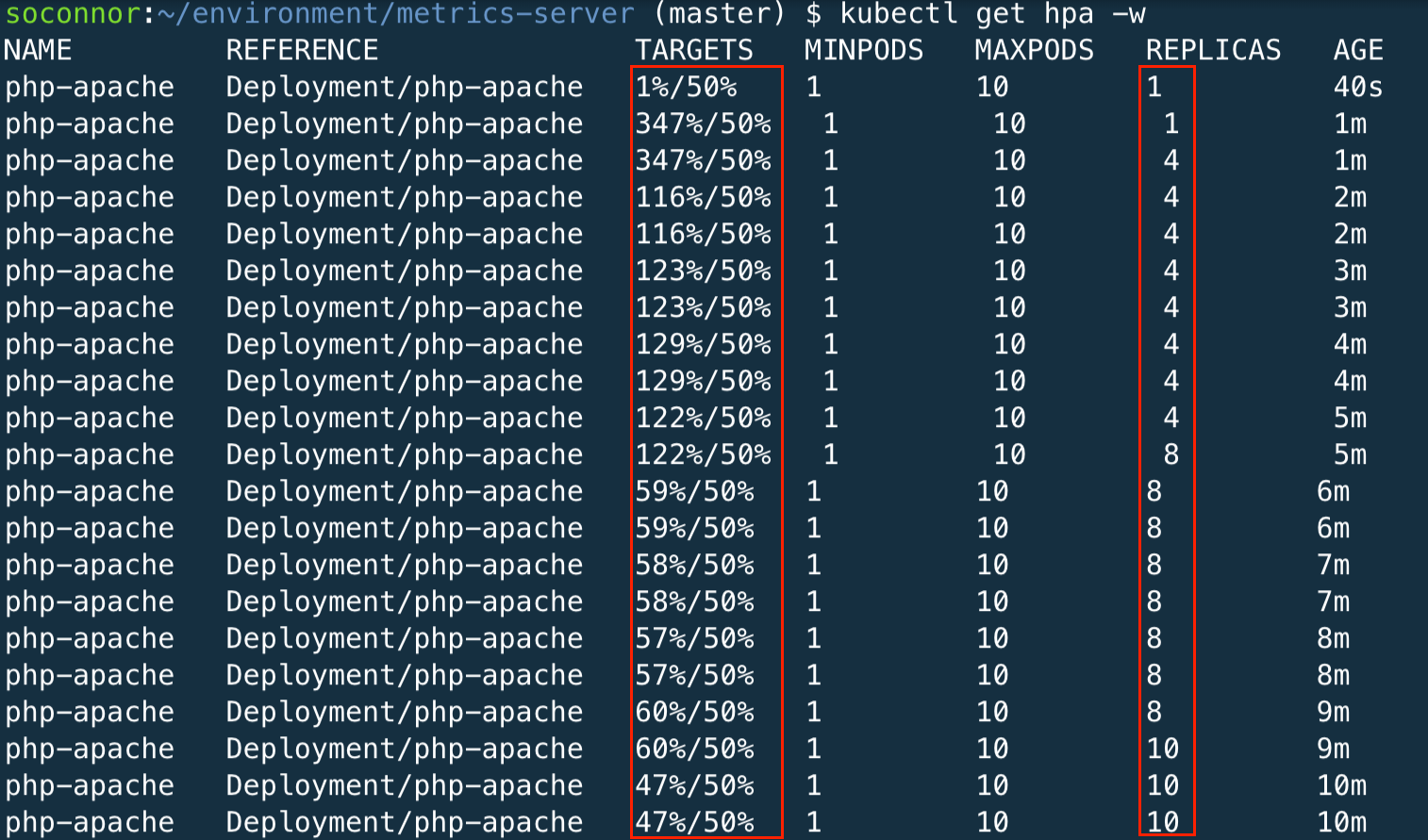
Agora você pode interromper o teste de carga (Ctrl C) que estava sendo executado no outro terminal. Você notará que o HPA levará lentamente a contagem da réplica ao número mínimo com base em sua configuração. Você também deve sair do aplicativo de teste de carga pressionando Ctrl D